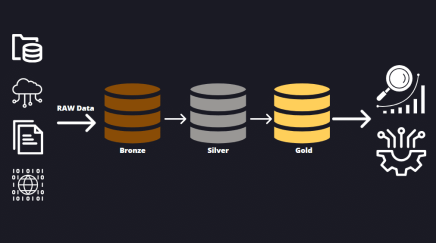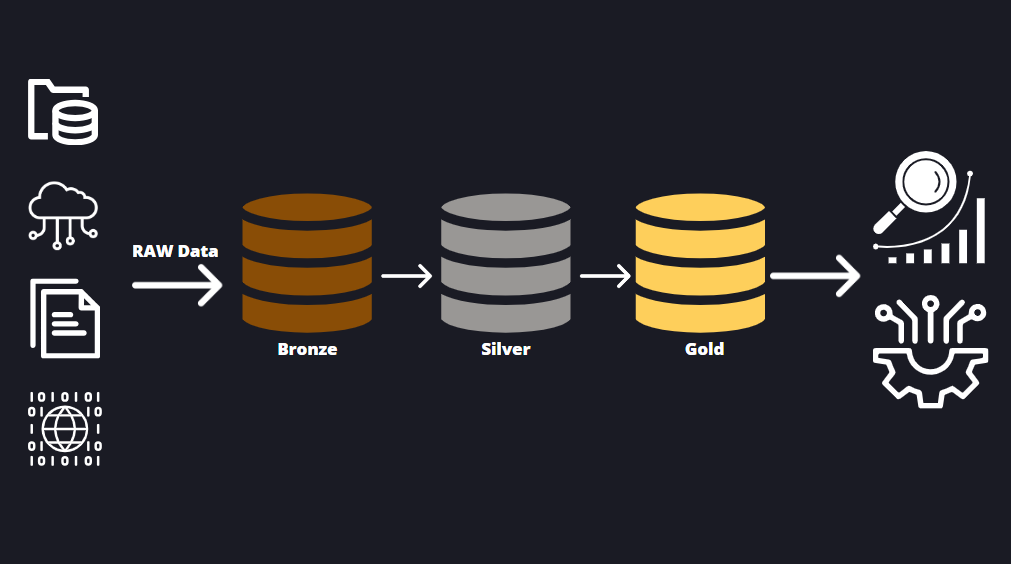
Data platforms today must balance scalability, governance, and performance while enabling seamless access to high-quality, analytics-ready datasets. The Medallion Data Architecture, originally introduced in lakehouse architectures, provides a structured approach for organizing data at different levels of refinement. While this concept is often associated with platforms like Databricks and Delta Lake, it is just as effective when implemented in Snowflake’s cloud data platform.
Snowflake’s separation of compute and storage, combined with its native support for semi-structured data, incremental processing, and security features, makes it an excellent fit for Medallion architecture. Organizations can improve data reliability, simplify transformations, and enhance performance for analytics and machine learning workloads by structuring data into Bronze, Silver, and Gold layers.
In this article, we’ll explore how Medallion Architecture can be applied within Snowflake and how it benefits organizations across industries such as finance, healthcare, and retail.
Understanding the Medallion Architecture
The Medallion Data Architecture is a framework for progressive data refinement, ensuring that raw data is structured, cleansed, and enriched before being consumed by business intelligence, reporting, and AI/ML models. It consists of three primary layers:
- Bronze Layer – Stores raw, unprocessed data from diverse source systems.
- Silver Layer – Cleans, validates, and standardizes data for transformation.
- Gold Layer – Provides enriched, aggregated, and analytics-ready datasets.
This structured approach offers several advantages:
- Data Lineage & Auditability: Each layer provides a checkpoint, making it easier to trace the origin and transformations of data.
- Incremental Processing: Changes are applied in stages, reducing redundancy and computational overhead.
- Flexibility Across Use Cases: Different layers support multiple needs—from real-time analytics to machine learning feature engineering.
- Data Quality & Governance: Issues such as duplicates, missing values, and schema inconsistencies are addressed progressively.
Unlike a traditional ETL (Extract, Transform, Load) approach, where data is processed upfront before landing in a warehouse, Medallion Architecture aligns more closely with ELT (Extract, Load, Transform) principles. This allows raw data to be retained, ensuring flexibility in reprocessing historical records, debugging errors, and enabling ad hoc analytics.
ETL vs. ELT
Traditional data pipelines followed an ETL (Extract, Transform, Load) approach, where data was extracted from source systems, transformed into a structured format in an external processing layer, and then loaded into a data warehouse. While this method worked well when computational resources were limited, it created challenges in scalability, flexibility, and performance. ETL required significant preprocessing, making it difficult to modify transformations without extensive rework. Additionally, transformations performed outside the data warehouse often led to data silos and governance issues, as teams had less visibility into the raw, unprocessed data.
With the rise of cloud-native architectures like Snowflake, organizations have shifted to ELT (Extract, Load, Transform), which inverts the process by loading raw data first and performing transformations directly within the warehouse. This approach leverages Snowflake’s scalable compute and storage, allowing transformations to be applied incrementally and in parallel. Since raw data is always retained, teams can reprocess data with different logic, backfill historical datasets, and support multiple transformation workflows without needing to modify source ingestion pipelines. ELT also ensures that data engineers, analysts, and data scientists have access to both raw and processed datasets, enabling richer analytics and faster experimentation.
The Medallion Architecture naturally aligns with ELT by structuring transformations across Bronze, Silver, and Gold layers. Data is first extracted and loaded into the Bronze Layer, ensuring a single source of truth that captures all incoming records. Transformations such as deduplication, validation, and enrichment occur progressively in the Silver and Gold layers, optimizing query performance while maintaining historical traceability. By adopting ELT, organizations gain greater flexibility, improved data governance, and faster processing speeds, all while reducing complexity in data engineering workflows.
Bronze Layer: Storing Raw Data in Snowflake
The Bronze Layer is the foundation of the Medallion Architecture, serving as the initial landing zone for raw data ingestion. This layer is designed to accommodate data from multiple sources in its original, unprocessed format, preserving the full fidelity of the source system.
- Raw Data Storage: Data is loaded from various sources, including databases, APIs, logs, IoT devices, and third-party feeds.
- Schema Flexibility: Supports semi-structured formats like JSON, Avro, Parquet, and CSV.
- Data Retention: Historical records are maintained, ensuring full traceability for auditing and debugging.
- Minimal Transformation: No major processing occurs except for basic ingestion validation (file format, structure, integrity checks, etc.).
Example: Loading Raw Data into Snowflake
CREATE OR REPLACE TABLE bronze_sales (
raw_data VARIANT,
ingestion_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP()
);
COPY INTO bronze_sales
FROM @my_s3_stage
FILE_FORMAT = (TYPE = 'JSON')
PATTERN = '.*sales_data.*';This example demonstrates storing raw JSON data in a VARIANT column inside Snowflake, allowing flexible ingestion without predefined schemas.
Silver Layer: Data Cleaning and Transformation
Once data is ingested into the Bronze Layer, it progresses to the Silver Layer, where the primary focus is on data quality, standardization, and transformation.
- Deduplication & Cleansing: Identifies and removes duplicate records and invalid entries.
- Schema Standardization: Converts semi-structured data into structured tables with defined data types.
- Enrichment: Joins data with reference tables, lookup values, or external datasets for additional context.
- Handling Missing Data: This technique applies imputation techniques such as filling NULL values, applying default values, or removing incomplete records.
Example: Transforming Bronze Data into Silver Table
CREATE OR REPLACE TABLE silver_sales AS
SELECT
raw_data:id::STRING AS sales_id,
raw_data:customer::STRING AS customer_name,
raw_data:amount::FLOAT AS sales_amount,
ingestion_timestamp
FROM bronze_sales
WHERE raw_data:id IS NOT NULL; This transformation extracts structured fields from JSON data, converting them into a clean, structured table for downstream analysis.
Gold Layer: Business-Ready Data for Analytics
The Gold Layer is the final stage of the Medallion Architecture, where data is refined into a fully optimized, analytics-ready state.
- Aggregations & Summaries: Pre-computed metrics such as monthly revenue, customer churn, or fraud risk scores.
- Optimized Performance: Data is indexed, partitioned, and clustered for faster query execution.
- Business-Focused Views: Designed for reporting dashboards, AI/ML models, and decision-making processes.
- Security & Governance: Implements role-based access control (RBAC) to restrict sensitive data access.
Example: Creating a Gold Table for Business Insights
CREATE OR REPLACE TABLE gold_sales_summary AS
SELECT
customer_name,
DATE_TRUNC('month', ingestion_timestamp) AS month,
SUM(sales_amount) AS total_revenue,
COUNT(DISTINCT sales_id) AS transaction_count
FROM silver_sales
GROUP BY customer_name, month;This query aggregates sales data at a monthly level, optimizing it for executive reporting and BI dashboards.
Platinum Layer: Advanced Analytics and AI Optimization
While the traditional Medallion Architecture consists of Bronze, Silver, and Gold layers, some organizations require an additional level of data refinement. This is where the Platinum Layer comes in—designed to support advanced analytics, AI/ML feature engineering, and high-performance optimization.
Unlike the Gold Layer, which focuses on business reporting and aggregated metrics, the Platinum Layer is tailored for predictive modeling, AI-driven decision-making, and real-time data applications. This layer is particularly beneficial for industries such as:
- Finance: Fraud detection models, credit risk scoring, algorithmic trading.
- Healthcare: Patient risk stratification, personalized treatment recommendations.
- Retail & E-commerce: Demand forecasting, recommendation engines, dynamic pricing.
Key Features of the Platinum Layer
- Machine Learning Feature Stores: Curates structured datasets optimized for AI/ML training.
- Real-Time Processing: Supports streaming data ingestion for up-to-the-minute analytics.
- Hyper-Optimized Query Performance: Uses materialized views, caching, and query acceleration techniques to enhance speed.
- Automated Data Science Pipelines: Integrates with platforms like Snowflake Snowpark, Databricks, or AWS SageMaker to run ML workflows.
Example: Creating a Platinum Table for Predictive Modeling
CREATE OR REPLACE TABLE platinum_customer_churn AS
SELECT
customer_name,
total_revenue,
transaction_count,
DATEDIFF(DAY, MAX(ingestion_timestamp), CURRENT_DATE) AS days_since_last_purchase,
CASE
WHEN DATEDIFF(DAY, MAX(ingestion_timestamp), CURRENT_DATE) > 90 THEN 1
ELSE 0
END AS churn_label
FROM gold_sales_summary
GROUP BY customer_name, total_revenue, transaction_count;In this example, the Platinum Layer creates a churn prediction dataset, helping businesses identify at-risk customers based on their purchasing patterns. This dataset can be fed into ML models to predict churn and trigger customer retention strategies.
When to Use the Platinum Layer?
Not all organizations need a Platinum Layer, but it becomes essential when:
- AI/ML and predictive analytics are a core part of business strategy.
- Streaming and real-time analytics are required for decision-making.
- Complex transformations and feature engineering are needed beyond traditional BI reporting.
- Compute-intensive workloads must be separated from operational analytics for performance reasons.
The Platinum Layer builds upon the Gold Layer to unlock advanced insights, automation, and AI-driven decision-making—a game-changer for data-driven enterprises.
Semantic Layer: A Unified Data Interface
As organizations move toward more complex and diverse data landscapes, the need for a semantic layer becomes apparent. The semantic layer acts as a unified interface between business users and raw data, providing a business-friendly view of the underlying data in the Medallion Architecture. This layer plays a crucial role in improving both the accessibility and understandability of data, ensuring that stakeholders across various business functions can work with data effectively without needing deep technical knowledge.
What is a Semantic Layer?
A semantic layer abstracts and simplifies the complexity of raw data by creating a business-oriented model that aligns directly with business goals and objectives. It provides a consistent set of business definitions, metrics, and KPIs that business users can easily query. Essentially, it allows users to interact with data using terms they understand, like “revenue,” “profit margin,” or “customer satisfaction,” rather than raw database schema or technical jargon.
For instance, instead of exposing business users directly to technical table names like sales_transactions or customer_data, the semantic layer can define an easy-to-understand metric like total_sales or active_customers based on a combination of data from various sources across the Medallion Architecture. This ensures that even non-technical users, such as product managers, marketing analysts, or executives, can gain insights without needing to understand the underlying technical complexity.
Benefits of a Semantic Layer in Medallion Architecture
- Improved Data Accessibility: The semantic layer creates an intuitive interface for business users, making it easier for them to understand and explore data without the need for SQL or technical expertise.
- Consistent Business Logic: By centralizing business rules and logic in one layer, organizations ensure that all company users work from the same definitions and calculations.
- Self-Service Analytics: With a semantic layer in place, users can independently query data and generate reports, reducing the dependency on data teams for routine tasks.
- Data Security and Governance: The semantic layer helps enforce data governance rules and ensure that users only access the data they are authorized to see. This is crucial for industries with strict compliance requirements, such as healthcare and finance.
Example: Creating a Semantic Layer View in Snowflake
To implement a semantic layer in Snowflake, organizations typically create views or materialized views that map the raw data from the Bronze, Silver, and Gold layers to user-friendly business metrics.
CREATE OR REPLACE VIEW semantic_sales_summary AS
SELECT
customer_id,
SUM(transaction_amount) AS total_sales,
COUNT(DISTINCT product_id) AS product_count,
CASE
WHEN SUM(transaction_amount) > 500 THEN 'High'
ELSE 'Low'
END AS customer_segment
FROM gold_sales_data
GROUP BY customer_id;In this example, a view is created on the Gold Layer sales data to provide an aggregated view of sales at the customer level. Instead of raw transaction data, business users can now work with total_sales, product_count, and customer_segment—simple, business-friendly metrics that help define the customer profile.
When Should You Consider Implementing a Semantic Layer?
A semantic layer is particularly useful when:
- Non-technical users need to access and understand complex data without direct interaction with the raw data or underlying databases.
- Multiple teams need to align on consistent definitions of key business metrics to ensure coherent decision-making.
- The data model is complex, and it’s important to present users with a simplified, business-friendly interface.
- Data security and governance policies need to be enforced while ensuring user-friendly data access.
Conclusion
By adopting Medallion Architecture in Snowflake, businesses can create a highly optimized and scalable data pipeline that efficiently handles everything from raw data ingestion to advanced analytics. The Bronze, Silver, and Gold layers provide a structured framework to refine and transform data into valuable insights, while the Platinum layer enables advanced data science capabilities.
Moreover, the inclusion of a semantic layer adds a crucial layer of accessibility and consistency, empowering business users to interact with data in a way that is intuitive and aligned with business goals. This enables organizations to improve decision-making, drive efficiency, and ultimately gain a competitive advantage in the market.
Implementing Medallion Architecture in Snowflake is about more than optimizing your data pipeline; it’s about building a solid foundation for data-driven success.